In the post Feasibility is optimal I suggested introducing a new barrier function to guarantee faster convergence towards the analytical center of a polytope. This turns out to be unnecessary or even detrimental, and in this post I will get into why. This post also presents a potentially new result relating to convergence for a class of central path methods for linear programming which I will call medium-step methods.
After digging around for literature on self-concordant functions I came across the book Convex Programming by Stephen Boyd and Lieven Vandenberghe. Chapter 9 of the book deals precisely with the kind of problem I'm wanting to solve, especially section 9.6.
I will also use the paper A polynomial-time algorithm, based on Newton's method, for linear programming by James Renegar. Using the notation from Renegar, the iteration bound on page 505 in Convex Programming, using optimal line search and 64-bit floating point accuracy, becomes:
All that remains is to work out a bound for . Remember that here is the barrier function, which we are minimizing. Large values of means slow convergence. In particular it is purely detrimental to add large quadratic terms as I suggested in the previous post. It may also be tempting to scale the barrier function down by some constant so as to reduce and thus the number of iterations, for example using . But such scaling violates the self-concordance constraint that sits at the heart of the complexity analysis that Boyd and Vandenberghe (really Nesterov and Nemirovski) provides:
which is violated for . It also makes sense that this kind of scaling should provide no benefit due to the affine invariant nature of the Newton method.
Finally, Boyd and Vandenberghe claim that Nesterov and Nemirovski provide an even tighter bound on the number of iterations, but I do not have access to the relevant work. The following PDF on Nemirovski's website may contain relevant information but I have not read it yet: Interior point polynomial time methods in convex programming
A conservative bound on Δ
To get started, let's borrow and adapt some of Renegar's notation. Renegar has the original system with . So has dimensions, and we have inequalities. Renegar also introduces extra inequalities, each one a copy of . These extra inequalities are moved forward at each step in the algorithm until we get close enough to the optimal solution. This is the "broom" I've written about earlier. Renegar ultimately uses , but provides convergence analysis for other values of which shall become useful.
When modifying a constraint in a system let and where the latter corresponds to the constraint we are changing. Using would be useless in what follows, but I will try to preserve the analysis for other values of in case it is useful to someone.
Each step in the algorithm has an associated centroid . Define the function as follows:
where correspond to the constraints that are not changing and to the one that does change (and copies of it, if any). In other words normalizes the coordinates by dividing them elementwise by . This means that where is all ones. Renegar also shows that for all feasible .
If we move the constraint some fraction towards , and if we started with a perfectly centered system () then Renegar shows that the distance from this point to the center of the new system () is bounded by
For this inequality has the solution
And for and not too small it is roughly
If for example and then . Note that we can never perfectly center any system due to limited machine precision, so in reality is somewhere around . This turns out to not matter in this case - this small extra contribution gets rounded off in the end.
The question now is how large can actually be? Let's first express it in terms of :
Let's further introduce , meaning we have:
Note that the sum over all elements in is zero (). Negative elements in contribute positively to (meaning raising it, worsening the iteration bound) whereas positive elements contribute negatively (improving the iteration bound).
We may obtain a simple upper bound for by first bounding and therefore . If we desire to move the constraint further than then we can do so in multiple steps. Next let have exactly one negative element, , and let's pretend that all other elements are zero. This cannot actually happen due to the zero sum constraint, so this upper bound is very conservative. We therefore have
Because of the convexity and strictly decreasing nature of there is no combination of two or more negative elements that will yield a higher upper bound on . We therefore have
This is already a useful result because it means we can move any constraint a substantial portion of the distance to the current center, and recenter the system in a reasonable amount of time. In particular we do not have to perform Newton steps as we would otherwise expect. Note that this does not help solve LP faster in general, because setting means overall convergence with respect to some objective function is slow. Using assumption (3.2) of Renegar with explicit:
With , and :
Which means that for every bit of desired accuracy we need to perform
iterations, each one consisting of up to 206 Newton steps. Letting and on the other hand results in only
iterations, each one only a single Newton step. We cannot use say with because then and will become large.
An even better bound on Δ
By making use of the sum constraint we can improve the bound on Δ.
Let be the vector with a single negative element, all other elements positive and equal and . For convenience let
then
Clearly , and
To see whether maximizes let us evaluate the gradient of the barrier function at projected onto the null space of . First the unprojected gradient:
We can perform the above mentioned projection by subtracting the average of the entries in from itself:
In other words:
But because butts up against and is perpendicular to the constraint, and points in the same direction as , therefore is locally optimal. Whether it is globally optimal is something that I conjecture is true, but I cannot prove it at present. At least one other local optimum exist, (signs merely flipped), but it can be shown to be inferior to its negative, as we shall soon see. Moving on, we have the following conjectural bound:
And in the limit:
Because we have limited we therefore have
If we use with signs flipped we instead get , which is inferior as previously stated. The iteration bound therefore, conjecturally, improves to:
We can do even better by optimizing the choice of . The following Octave code shows that is optimal:
octave:58> d=0.01:0.001:0.4; b=d./(1-d); it=(ceil(288*(-log(1-b)-b))+6).*ceil(1./d/3); plot(d,it); [i,j] = min(it); it(j), d(j)
ans = 26
ans = 0.1670
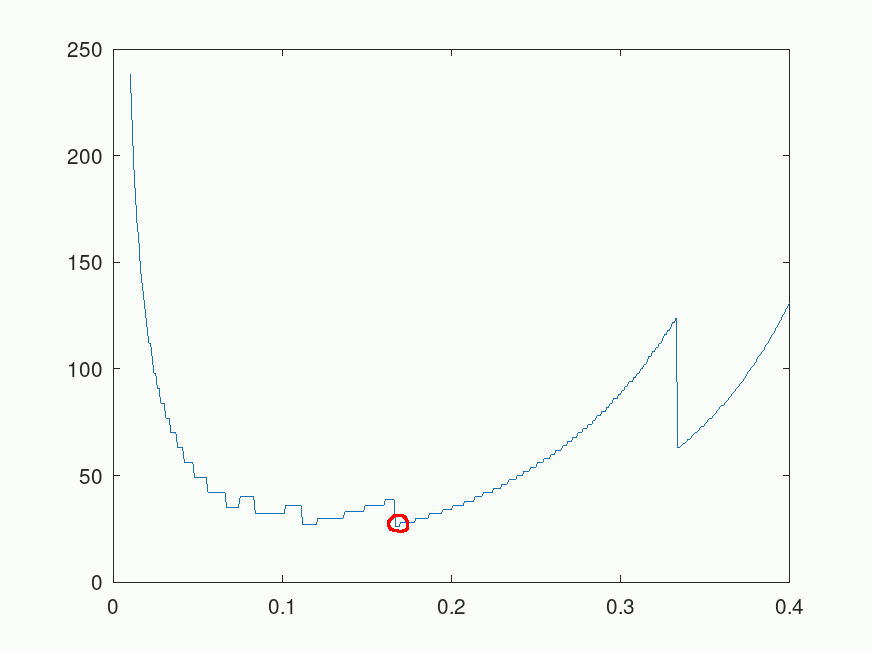
So as few as Newtons steps will perform the same job that would otherwise require 62 steps with . So conjecturally we are nearly an order of magnitude faster than the 206 figure in the previous section.
Medium-step
The term medium-step comes about for two reasons: the existence of the term long-step in the literature and the much shorter steps taken in Renegar's paper compared to what is done here.
Renegar uses whereas I use above. We could therefore call Renegar's short-step. It requires iterations. On the other extreme, the type of predictor-corrector methods often used in practice are known as long-step methods. They use , sometimes stepping as far as 99.9% of the distance to the boundary of the system. Todd and Ye demonstrate that these methods have worst-case performance of and, if I understand correctly, they remain .
Because the chosen above is inbetween these two extremes I have chosen to call the method medium-step. Note again that this result is only useful if we seek to remain in the center of a linear program. It is not useful if one seeks to optimize some objective function .
Future work
Further theoretical improvements could be made by analyzing what I will call medium-step predictor-corrector methods. By computing the tangent to the central path using a short step, a line search can be performed for finding a better initial guess in the system updated with . This is likely to bring down the number of Newton steps. By how much I am not sure. Note that computing this tangent itself costs a small number of Newton steps. On the other hand the system is likely to be better conditioned compared to just after a medium-step update, meaning these Newton steps are cheaper to compute.
Closing remarks
I started writing this post around 2023-03-05, so in total I've been obsessing about this specific problem for roughly seven weeks. Initially I thought I had a much stronger result than I actually do, so quite a bit of time was spent making sure I don't overstate the result. In the process I've learned even more about barrier methods and self-concordant functions.